#LLM are bad at logical reasoning (syllogism)...
But they may still be better than humans, and sometimes less sensitive to human reasoning biases:
https://arxiv.org/abs/2311.00445
There are many types of adapters for LLM; although LoRA still seems to perform best
in most cases, there are interesting advantages for other types:
- for a review: https://arxiv.org/abs/2304.01933
- 2 interesting adapters: AdaMix and ladder side-tuning; a better extension of LST with low-rank att is given in https://arxiv.org/abs/2402.04009
TrustLLM: leaderboard for evaluating trustfulness of LLMs:
https://trustllmbenchmark.github.io/TrustLLM-Website/index.html
secret sauce for long-context LLM: https://blog.gopenai.com/how-to-speed-up-llms-and-use-100k-context-window-all-tricks-in-one-place-ffd40577b4c
best practices for synthetic data for LLMs, by Google: https://arxiv.org/abs/2404.07503
GoEX enables users to verify post-facto the output of an LLM agent / actions,
while confining the LLM within a secure runtime and enabling "undoing" its actions
before going live: https://arxiv.org/abs/2404.06921
Combining context compression, retrieval and LoRA leads to LLoCO, a method to capture long
contexts for vanilla LLMs: https://arxiv.org/abs/2404.07979
In the series of "transformers for search", here is Searchformer, that encodes the
dynamics of the old-classic A* algorithm as tokens, and trains an enc-dec
model to minimize the number of steps. It ends up being faster than baselines for
sokoban solving: https://arxiv.org/abs/2402.14083
New paper for continual pretraining: Sailor, which shows the
importance of carefully tuning the learning rate to prevent
forgetting: https://arxiv.org/abs/2404.03608
Quite interesting and reasonable point of view for CL.
It's also part of the bunch of papers that show that we really
don't need very fancy/complex architectures, and that just
careful hyper-parameter tuning of the vanilla transformer does the job...
Another milestone in long-range attention, from Google: https://arxiv.org/pdf/2404.07143.pdf
The trick is to save the past KV cache into a compressed memory, at every layer, and to
inject it (kinda just-forward recurrence) into the attention when processing the next segment.
This leads to potentially infinite context length.
Great set of small tutos to try various applications, RAG-based, LLM evaluations, etc.
with open-souce models: https://huggingface.co/learn/cookbook/index
Removing complete layers, up to 40% of them for llama,
followed by a bit of PEFT healing, doe snot degrade that much:
https://arxiv.org/abs/2403.17887
Nice post with details of the Yi-9B model:
it has been obtained by expanding the Yi-6B LLM with additional layers
before further training on 800b tokens. Growing networks strike back!
Another "surprising" (well, may be not that much anymore...) heuristic is
to train with a constant LR, and increasing the batch size when the loss
does not decrease any more:
https://huggingface.co/blog/lorinma/yi-9b-divedeep
wanna train an LLM ? *the* video you wanna watch: https://www.youtube.com/watch?v=2-SPH9hIKT8
multimodel LLMs: https://arxiv.org/abs/2401.13601
Ferret https://ar5iv.labs.arxiv.org/html/2310.07704
GILL https://arxiv.org/abs/2305.17216v3
MM1 https://arxiv.org/abs/2403.09611
infinite-lenth context generalization: https://arxiv.org/pdf/2308.16137.pdf
Idnetifies and analyses the 3 mains factors that prevent context length generalization
(even with relative positional encodings), and proposes a lambda-shaped mask.
Sophia is two times faster than Adam;
Sophia lightly estimate the diagonal Hessian:
https://arxiv.org/pdf/2305.14342.pdf
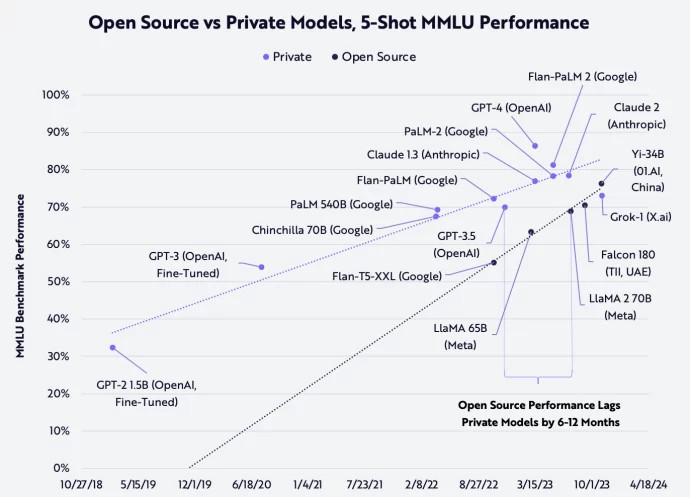
Open vs. closed-source LLMs trend:
Source: ARK Investment Management LLC, 2023. Data as of November 10, 2023